|
|
 |
|
The preceding discussion identified the components of a
broad framework for a common approach to cataloguing. The
implementation of such a framework, described below, is
directed primarily to computerized databases, but it deals
with concepts that are relevant to other approaches to cataloguing.
Choosing an Appropriate Data Structure
The structure and content of traditional catalogue entries
reflect the formats developed for conventional methods of
dissemination. Computerized records for architectural drawings
and archives offer an opportunity to expand on traditional
approaches. In particular, computer-based systems eliminate
the need to record information in the form or forms in which
it is to be viewed. The objective is an ability to generate
printed—and in the future illustrated—catalogue
entries with a minimum of effort, but also to be able to
retrieve by as many individual pieces of information as
possible. Information for entries must therefore be compiled,
recorded, stored, and made accessible in ways that allow
both these aims to be achieved.
Numerous considerations are worth keeping in mind in the
design process, among them the level of skill required to
operate a system, the resources required to capture information,
the speed of retrieval, and the quantity of information
that can be stored. The ability of a computer-based system
to meet the requirements of its users depends not only on
the information content, but on the data structure
in which it is held. Data structure refers to the
entities within an entry, the categories of which they are
composed, and all the relationships that are established
within this framework. The suitability of any data structure
may be determined in part by asking the following questions:
- Can it be used to record all the categories of information
required?
- Will it hold that information in a way that is both
logical and consistent?
- Is it possible to retrieve information from the categories
that are designated as access points in all the combinations
that are required?
An important aspect of this process is the decision whether
to adopt a flat or a relational data structure.
In the former, all information about an item, its subject,
related people, etc., resides within a single file, while
in the latter, categories of information are distributed
among a number of files (often referred to as tables).
The advantage of flat structures is that they can be relatively
cheap to implement and easy to use. This ease of use results
from the fact that all the information that pertains to
an entry is held in a single file, making the retrieval
of that information a fairly simple process. The great disadvantage
of flat structures is, however, their lack of flexibility.
This relative inflexibility means that they are not well
suited to coping efficiently with relationships between
the categories of information of which an entry is composed.
For example, a repository may have to catalogue a single
drawing that depicts several subjects, some of which may
be depicted—individually or collectively—by a
number of other drawings in the collection. In the same
way, a single draftsman may have been responsible for a
number of drawings, while a single drawing could be the
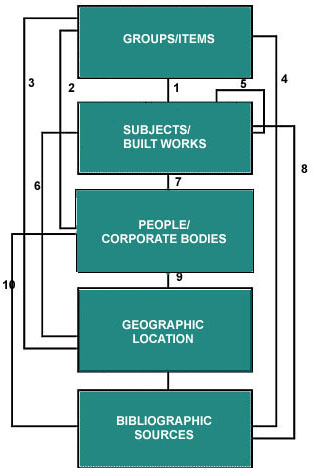
work of more than one draftsman. Similar relationships—sometimes
characterized as many-to-many relationships—will exist
between all the principal categories of information into
which an entry can be divided: in the context of the Guide,
groups/items, subjects/built works, people/corporate
bodies, and geographic locations. Some relationships
between these can be expressed as follows:
- Items will have geographic locations, makers,
and subjects.
- Subjects/Built Works may be depicted by items,
may be related to people, and may have geographic
locations.
- People may have made items, may be related to
subjects and built works, and may have known
loci of activity.
- Geographic Locations may be locations of items,
subjects, or built works, or be the loci
of activity of people.
Other principal relationships are shown below:
In other words, each of these areas is related to all the
others. An attempt to implement this model on a flat system
would result in an unwieldy structure that duplicated a
great deal of information. The constraint of expending time
and effort in duplicating information of this sort has led
many institutions with flat systems to opt for relatively
unambitious and therefore limiting records that typically
do not allow for ancillary information such as a biography
within an entry for an item.
The most common solution to this problem, and one which
is being adopted increasingly, is to use a relational database
system. Relational databases allow for data structures that
hold the information relating to a single entry in a number
of files. The principal files, or groups of files, correspond
to principal areas of information: groups and items, subjects,
built works, people, corporate bodies, and geographic locations.
Categories of information extrinsic to groups and items
are stored in authority files, those files being linkable
to all the other files needed to answer a particular query,
or for the creation of a catalogue entry. A relational structure
implemented along these lines enables the user to make requests
such as: "find all items (item file) that represent
the Ponte Vecchio (subject file) by draftsmen
(persons and corporate bodies file) whose locus of activity
was France (geographic location file)."
The strength of the relational database, then, lies in
its ability to mirror relationships between entities, and
to make it possible to record and retrieve information by
relating fields that reflect those entities. The weakness
of this approach is that a number of specific links must
be made between the files in order to answer a query. Also,
the more fields and groups of fields that need to repeat,
the more complex the process of extracting information from
them. The corollary of a gain in flexibility of structure
can, therefore, be a loss of flexibility in use. The more
complex the structure, the more time-consuming it can be
to add information to it and retrieve from it. It is important,
therefore, to strike a balance between structural complexity
and ease of use.
Recording and Relating Information
The extent to which the categories of information defined
in the Guide can be adopted and the ways in which
they may be implemented depend on the type of retrieval
system proposed. The Guide does not seek to recommend
a particular approach or specify a data structure. There
are, however, considerations of data structure implicit
in the definition of categories and the relationships between
them, since implementation would require either a highly
linked relational data structure or a great deal of repetition
of individual categories or groups of categories. Some general
guidelines on implementation given here cover:
 Recording multiple pieces of information
within a record Recording multiple pieces of information
within a record
Preserving hierarchical relationships
within and between categories of information
Recording information of the same
type in different contexts
Relating records
Recording multiple pieces of information
for a single category
One of the problems of designing any retrieval system is
that of recording different pieces of information that belong
to the same category, e.g., when two or more architects
designed a particular building. In a manual system this
would be handled by making a separate index card for each
architect. For computerized records there are a number of
possible approaches, some of which are specific to certain
types of software. One solution is to record all these pieces
of information in the same field, in the form of structured
free text. By using punctuation marks or other delimiters,
more than one piece of information may be cited. This process
is sometimes called subfielding.
The following examples demonstrate ways in which to record
more than one medium for an architectural drawing.
Medium:
|
brown ink, brown wash, black chalk
|
Another solution is to create a predetermined number of
occurrences of a field and ensure that only a single piece
of information appears in any one.
Medium 1:
|
brown ink
|
Medium 2:
|
brown wash
|
Medium 3:
|
black chalk
|
A third is to use a relational system capable of allowing
for an unlimited number of repetitions of individual fields,
or groups of fields.
Medium:
|
brown ink
|
|
brown wash
|
|
black chalk
|
There are limitations to all three of these options. The
first is the easiest to implement, but offers the lowest
potential for retrieval and manipulability of information.
The second is relatively unwieldy and inflexible. It also
creates a problem for retrieval by requiring searches to
be run on every occurrence of a field in order to determine
whether the information sought is present. Adopting the
third option increases the complexity of the data structure,
but it does increase its flexibility.
Another advantage of relational structures is their ability
to allow for the creation of additional occurrences not
only of individual fields, but also of groups of fields
holding related pieces of information, e.g., the categories
of information that combine to provide the geographic location
of a building. The ability to repeat groups of fields also
allows the recording of information such as the past name(s)
of a geographic location as well as its present one(s),
and the name in the vernacular as well as in the language
of the repository. This is a particularly useful way of
providing cross-referencing within authority records.
Preserving hierarchical relationships within and between
categories
Proper names and generic terms may subsume narrower terms
and be subsumed by broader terms. If both broad and narrow
terms are entered in the same field, the potential for retrieval
of information held in that field will be reduced. For example,
if a search is made in a field designated Building Type
(by function/form) using the term house, the only
records retrieved will be those entered as such. The query
will not find all the houses that are recorded using narrower
terms for house, such as cottage or, narrower
still, cottage ornée. One solution is to have
fields corresponding to more than one level of description,
e.g., Building Type (Broad) and Building Type (Narrow).
Another is to link the field to an online thesaurus that
is structured in such a way that a query results in the
retrieval not only of records in which that term was used,
but also of those in which any children of the term appear.
There can be hierarchical relations between categories,
as well as within them. Examples of categories that comprise
a number of pieces of information at different hierarchical
levels include Administrative Unit and Geographic Location.
In the case of the former, repositories may wish to have
a separate field for each level of the hierarchy. This would
make possible retrieval, sorting, and display at the level
of the administrative unit, not just at that of the repository
as a whole. Similarly, the recording of a geographic location
as a number of separate but related fields provides a greater
degree of flexibility in retrieving and manipulating locational
information (see Geographic Locations).
Recording information of the
same type in different contexts
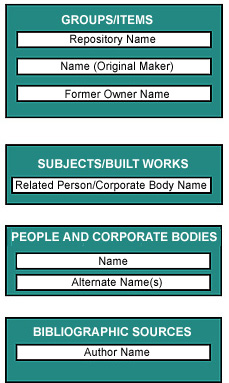
One of the best examples of recording information of the
same type in different contexts to be found in the Guide
is the names and roles of people and corporate bodies. Such
names are recorded in the following contexts:
- Name in the People/Corporate Bodies authority file
- Alternate Name in the People/Corporate Bodies authority
file
- Name [of origin/maker] in the Groups/Items file
- Name [of former owner] in the Groups/Items file
- Related Person/Corporate Body Name in both the Groups/Items
file and the Subjects/Built Works file
- Author Name in the Bibliographic Sources authority file
In a relational system all these names could be recorded
via data entry screens designed to capture the particular
categories of name, but might be stored in a single location:
the People/Corporate Bodies authority file. The advantage
of this solution is that only a single occurrence of the
name is stored, and that name is authority-controlled. Queries
on name could be carried out across the database by searching
a single field, rather than seven. If preferred and alternate
names are recorded in a single field, there must be a mechanism
for indicating the status of individual names (e.g., preferred
or alternate); see Ill. 8. This would make it possible
to see at a glance which name in an authority record is
the preferred one, and to screen out alternate versions
for some displays of the information.
Another example of a concept recorded in different contexts
is the notion of roles, which are recorded in the following
categories:
- Life Role(s) in the People/Corporate Bodies authority
file
- Author Role in the Bibliographic Sources authority file
- Role (Broad) and Role (Narrow) in Groups/Items
- Related Role in Groups/Items and Subjects/Built Works
A person, or corporate body, can have a number of roles,
each of which is specific to the context in which it is
recorded (e.g., as the draftsman of a particular
drawing, or the architect of a built work). If roles
are recorded, but are not linked to their contexts, then
a user might be able to find out that a particular person
had been both a draftsman and an architect, but
not which of those roles applied to particular items and
subjects. It is desirable, therefore, to link people and
corporate bodies to the groups or items, subjects, or built
works with which they were involved via the roles they played.
Relating one record to another
A data structure should provide some means both of relating
the entities that combine to create a record and of relating
one record to another, e.g.,
- A record for a group to a record for an item within
that group
- An authority record for an architect to a record for
his or her partner
- A record for a complex of buildings to a record for
one of the buildings that make up the complex
When records of the same type are related, they have a
recursive relationship. The links that establish
these relationships can be provided in a number of ways.
One of the most common is to enter the primary record number
or some other unique identifier of the related records in
a field designed for that purpose.[1] The
fact that two or more records have this value in common
makes it possible for the system to recognize that a relationship
exists between them. The unique numeric identifiers used
to create these links in relational systems are called keys.
|
|
|
|