In the current environment of global access to the universe of electronic resources, the importance of metadata has only increased. Metadata standards and their structures are in a state of flux as they aim to accommodate “futuristic” models of information sharing. These standards reflect the functionality of how information and knowledge are stored and expressed for machine processing and how search engines can serve as better filters for discovery. In recent years we have witnessed a transition from print-based content to content that is born in digital form or made available simultaneously in multiple formats. All of this is accompanied by a blurring of the lines between articles in journals, chapters in books, books that have been digitized in their entirety, accompanying data, and structured or unstructured data that is archived as content.
There are still no magical means for perfect, seamless access to the right information in the right context. Institutions of all kinds have transitioned to automated systems to provide access to their collections and manage their assets or repositories for all their content, while institutions or communities support multiple repositories that may or may not be interoperable. Individual institutions, or communities of similar institutions, have created shared metadata standards that organize this content. These standards might include metadata elements or fields1 with their definitions, codified rules or best practices for recording the information, and controlled lists of terms to populate access fields. We need to remember that these legacy or preexisting systems still may serve only specialized knowledge communities. Each community maintains its own structure and rules for fields of access, description, and vocabulary control (if any) that best serve it. It is when a community shares content with others or wants to reuse the information for other purposes that problems of interoperability arise. Achieving seamless and precise retrieval of information objects is not a simple process. Well-structured and carefully mapped metadata plays a fundamental role in reaching this goal.
The development of sophisticated tools to find, access, and share digital content, such as link resolvers, the Open Archives Initiative Protocol for Metadata Harvesting (OAI-PMH) harvesters, and the emergence of the so-called Semantic Web have increased users’ demand for the ability to search simultaneously across many different metadata structures. This has motivated institutions either to convert their legacy content developed for in-house use to standards more readily accessible for public display or sharing or to provide a single interface to search many heterogeneous databases or web resources at the same time. Crosswalks are at the heart of our ability to make this possible, whether they support conversion of data to a new or different standard, to harvest data from multiple resources and repackage it, to search across heterogeneous resources, or to merge information.
Definitions and Scope
For the purposes of this chapter, we will refer to mapping as the intellectual activity of comparing and analyzing two metadata schemas, and to crosswalks as the visual product of mapping. A crosswalk is a table or chart that maps the relationships and equivalencies between two or more metadata formats.2 The first section of this chapter will deal with the different situations where crosswalks are used. The second section will focus on metasearching and harvesting metadata for reuse and enhancement by service providers. The chapter closes with case studies that serve to illustrate the issues.
Over the years many different terms have been used for what is known as metasearching: “federated searching,” “broadcast searching,” and “parallel searching,” to name just three. We hear about search portals and find expressions like “screen scraping.” In this publication we will follow the National Information Standards Organization (NISO) Metasearch Initiative’s definition of metasearching as “search and retrieval to span multiple databases, sources, platforms, protocols, and vendors at one time.”3 Harvesting is not a search protocol; it is a protocol that allows the gathering or collecting of metadata records from a variety of repositories or databases in order to create union catalogs or “federated” resources. As of this writing, the OAI-PMH is the prevalent protocol being used to harvest metadata.4
Metadata Mapping and Crosswalks
In comparing two or more metadata element sets or schemas, distinctions and similarities must be understood on multiple levels to evaluate the degree to which they are interoperable. One definition of interoperability is “the ability of different types of computers, networks, operating systems, and applications to work together effectively, without prior communication, in order to exchange information in a useful and meaningful manner. There are three aspects of interoperability: semantic, structural, and syntactical.”5
Semantic mapping is analyzing the definitions of the elements or fields so as to determine whether they have the same or a similar meaning. Crosswalks are the visual representations or “maps” that show these relationships.6 A crosswalk supports the ability of a search engine to query fields with the same or similar content in different databases; in other words, it supports “semantic interoperability.” Crosswalks are not only important for supporting the demand for “one-stop shopping,” or cross-domain searching, they are instrumental for converting data in one format to another format that is more widely accessible.
Structural interoperability refers to the presence of data models or wrappers that specify the semantic scheme being used. For example, the Resource Description Framework (RDF) is a model that allows metadata to be defined and shared by communities.7
Table 1. Example of a Crosswalk of a Subset of Elements from Different Metadata Schemes
| CDWA | MARC | EAD | Dublin Core |
|---|---|---|---|
| Object/Work-Type | 655 Genre/form | <controlaccess><genreform> | Type |
| Titles or Names | 24Xa Title and Title—Related Information | <unittitle> | Title |
| Creation–Date | 260c Imprint—Date of Publication | <unitdate> | Date.Created |
| Creation-Creator-Identity | 1XX Main Entry 7XX Added Entry | <origination><persname><origination><corpname><origination><famname><controlaccess><persname><controlaccess><corpname> | Creator |
| Subject Matter | 520 Summary, etc.6xx Subject Headings | <abstract><scopecontent><controlaccess><subject> | Subject |
| Current Location | 852 Location | <repository><physloc> |
Table 2. Example of a Crosswalk: MARC21 to Simple Dublin Core
| MARC fields | Dublin Core elements |
|---|---|
| 130, 240, 245, 246 | Title |
| 100, 110, 111 | Creator |
| 100, 110, 111, 700, 710, 711 | Contributor |
| 600, 610, 630, 650, 651, 653 | Subject / Keyword |
| Notes 500, 505, 520, 562, 583 | Description |
| 260 $b | Publisher |
| 581, 700 $t, 730, 787, 776 | Relationship |
| 008/ 07-10 260 $c | Date |
Mapping metadata elements between standards is only one level of crosswalking. At another level of semantic interoperability are the content standards or cataloging rules for populating metadata elements or fields, such as the form for personal names, encoding standards for dates, and thesauri used for topical or subject headings. A weakness of crosswalks of metadata elements alone is that the results of a query will be less successful if the name or concept is expressed differently in each resource. By using controlled vocabularies for identifying people, places, corporate bodies, and concepts, it is possible to greatly improve retrieval of relevant information associated with a particular concept; it is hoped that if linked open data makes the Semantic Web a reality, this kind of vocabulary-enhanced search and retrieval will become much more prevalent than it is at present.
Some databases (such as library and other discovery systems) provide access to controlled terms along with cross-references for variant forms or words that point the searcher to the preferred form. This optimizes the searching and retrieval of digital objects (bibliographic records, images, sound files, etc.). There is currently no universal authority file that catalogers, indexers, and users can consult. Each cataloging or indexing domain tends to develop its own thesauri or lists of terms designed to support the research needs of a particular community. Crosswalks have been used to migrate the data structure of a vocabulary from one format to another, but only recently have there been projects to map the data content that actually populates that structure.8
To meet the need to share records between international libraries, the Online Computer Library Center (OCLC) and the Library of Congress have spearheaded an international initiative to develop the Virtual International Authority File (VIAF).9 As of this writing the VIAF is a file of millions of authority records for personal and corporate names from libraries and other institutions from all over the world that supports data sharing and exchange and enhances retrieval. This is important when searching the records of many databases simultaneously, where precision and relevancy become even more crucial. This is especially true if one is searching single-search query bibliographic records, records from citation databases, and full-text resources at the same time. Integrated authority control significantly improves both retrieval and interoperability in searching resources like these that are aggregations of disparate metadata records.10
The Gale Group solved the problem of multiple-subject thesauri by creating a single thesaurus and mapping the controlled vocabulary from the individual databases to that thesaurus. It is unclear to what extent this merging of data compromised the depth and coverage of the controlled terms in the individual databases.11
The Simple Knowledge Organization System (SKOS), a project developed by the World Wide Web Consortium’s Semantic Web Best Practices and Deployment Working Group, is a set of specifications for organizing, documenting, and publishing taxonomies, classification schemes, and vocabulary schemes such as thesauri, subject lists, and glossaries or terminology lists within an RDF framework.12 SKOS is a specific application that is used to express mappings between knowledge organization schemes. The ability to map vocabularies as well as metadata element standards will strengthen the ability of search engines to search across heterogeneous databases more effectively.13
Crosswalks for Repurposing and Transforming Metadata
The notion of repurposing metadata covers a broad spectrum of activities: converting or transforming metadata from one standard to another; migrating metadata from one legacy standard to a different one; integrating two metadata standards; and harvesting or aggregating metadata created using a shared community standard or different metadata standards. Dushay and Hillmann note that the library community has an extensive and successful history of aggregating bibliographic metadata records encoded in the MARC (Machine-Readable Cataloging Record) format created by many different libraries that share content standards (Anglo-American Cataloging Rules, Library of Congress authorities and classifications, and so on). However, aggregating metadata records from different repositories may create confusing display results, especially if some of the metadata was automatically generated or created by institutions or individuals that do not follow best-practice standards.14
Conversion projects transfer metadata fields or elements from one standard to another. Institutions have converted data for a variety of reasons; for example, when upgrading to a new system because the legacy system has become obsolete, or when the institution has decided to provide public access to some or all of its content. Conversion is accomplished by mapping the structural elements in the older system to those in the new system. In practice, there is rarely the same degree of granularity among all of the fields in the two systems, which makes the process of converting data from one system to another more complex (see table 1). Data fields in the legacy database may not have been well defined or may contain a mixture of types of information. In the new database, this information may reside in separate fields. Identifying the unique information within a field in order to map it to another field may not always be possible; manipulating the same data several times before migrating it may be necessary.
Some of the common misalignments that occur when mapping between metadata include:15
- Fuzzy matches: A concept in the original database does not have a perfect equivalent in the target database. For example, when mapping the creation-creator-identity-nationality/culture/race elements in Categories for the Description of Works of Art (CDWA)16 to the subject element in Dublin Core, which does not have the same exact meaning. Since the Dublin Core subject element is a much broader category, this is a “fuzzy” match.
- Hybrid records: Although some metadata standards (e.g., Dublin Core) follow the principle of a one-to-one relationship between a metadata record and an “item”—be it analog or digital—in practice many memory institutions use a single metadata record to record information about an original object as well as its digital surrogate, thus creating a sort of “hybrid” record. When migrating and harvesting data, this may pose problems if the harvester cannot distinguish between the elements that describe the original item and those that describe the digital surrogate.
- One element into many: Data that exists in one element in the original schema may exist in separate elements in the target database. For example, the CDWA creation-place element may appear in the subject and the coverage elements in Dublin Core.
- Many elements into one: Data in separate elements in the original schema may be in a single element in the target schema. For example, in CDWA the birth and death dates for a “creator” are recorded in the creator-identity-dates element as well as in other elements, all apart from the element for the creator’s name. In the MARC format, birth and death dates are a “subfield” in the string for the “author’s” name.
- No correspondence: There is no element in the target schema equivalent to the element in the original schema, and unrelated data may be forced into a single “bucket” with unrelated or loosely related content.
- Evolving standards: In some cases, the original “standard” is actually a mix of standards that evolved over time. Kurth, Ruddy, and Rupp have pointed out that even in transforming metadata from a single metadata standard, it may not be possible to use the same conversion mapping for all records. The Cornell University Library metadata project revealed the difficulties in “transforming” MARC library records to TEI (Text Encoding Initiative). Not only had the use of MARC in the library evolved over time, but the rules guiding how content was added had changed from pre–Anglo-American Cataloguing Rules to AACR2rev.17 Some MARC subelements were dropped, and others were added, so that various communities could more easily reuse library records for their own purposes.18 The conversion of library records created according to AACR2rev in order to make them conform with the new cataloging standard, Resource Description and Access (RDA), is beyond the scope of this chapter. In the years to come, as more and more libraries create original bibliographic records according to RDA, interesting challenges are sure to emerge.
- Incomplete correspondence: In only a few cases does the mapping work equally well in both directions, due to differences in granularity and community-specific practices (see number 2 above.) The large Getty metadata crosswalk19 was created by mapping in a single direction: CDWA was analyzed, and other data systems were mapped to its elements. However, there are some types of information recorded in MARC that are lost in this process; for example, the publisher and language elements are important in library records but are less relevant to CDWA.
- Differing structures: One metadata set may have a hierarchical structure with complex relationships while the other may have a flat file organization—EAD (hierarchical) versus MARC (flat), for example.20
Metasearching
The number of metadata standards is growing, and it is unrealistic to think that every standard can be mapped or converted to a common standard that will satisfy both general and domain-specific needs. (At one time it was believed that Dublin Core would be the “Holy Grail” in this sense, but practical experience in a variety of metadata communities has proved otherwise). An alternative is to maintain the separate databases that have been developed to support the needs of specific communities in their original schemas and to offer a search interface that allows users to search across the various heterogeneous databases simultaneously. This can be achieved through a variety of methods.
The best-known and most widely used metasearch engines in the library world are based on the Z39.50 protocol.21 The development of this protocol was initiated to create a “virtual” union catalog that would enable libraries to share their cataloging records (then all in the MARC format). With the advent of the Internet, the protocol was extended to enable searching of abstracting and indexing services and full-text resources when they were Z39.50 compliant. Some information professionals touted the Z39.50 protocol as a “one-stop-shopping” solution that would provide users with seamless access to all authoritative information about a particular search query. At the time of its initial implementation, the Z39.50 protocol had no competitors, but it was not without its detractors.22
The library community is divided over the efficacy of metasearching. When are “good enough” search results really good enough? Often the results created through a keyword query have high recall and low precision, leaving the user at a loss on how to proceed. Users who are familiar with web search engines will often take the first hits generated by a search regardless of their suitability. Authors have pointed to the “success” of Google to reaffirm the need for federated searching without referring to any studies that evaluate the satisfaction of researchers.23 A preliminary study conducted by Lampert and Dabbour on the efficacy of federated searching laments the fact that studies have focused on technical aspects without considering users’ search and selection habits and the impact of federated searching on information literacy.24 Unfortunately, this is a familiar phenomenon in the world of library technology: frequently, the emphasis is on technical issues and solutions, while user needs and behavior and user interface and usability issues tend to be neglected.
What are some of the main issues associated with metasearching? In some interfaces, results may be displayed in the order retrieved or by computer-determined relevance (which may have little or nothing to do with how relevant the results actually are to the user’s query), either sorted by categories or integrated. Having the choice of searching a single database or multiple databases allows users to take advantage of the specialized indexing and controlled vocabulary resources of a single database or to cast a broader net. There are several advantages of a single gateway or portal to information. Users are not always aware which of the many databases that exist for a particular domain will provide them with the best information, or they may not be aware of them at all. Many libraries have attempted to list domain-specific databases by categories and provide brief descriptions of them, but users tend not to read lists, and this type of “segregation” of resources neglects the interdisciplinary nature of research. Few users have the tenacity to read lengthy A–Z lists of databases or to ferret out databases relevant to their queries when they are “buried” in lengthy menus. On the other hand, users can be overwhelmed by large search result sets and may have difficulty finding what they need, even if the results are sorted by relevancy ranking.25
Some of the commercial “metasearch” engines for libraries are still using the Z39.50 protocol to search across multiple repositories simultaneously.26 In simple terms, this protocol allows two computers to communicate in order to retrieve information; a client computer will query another computer, called a server, which provides a result. Libraries employ this protocol to support searching other library catalogs along with abstracting and indexing services and full-text repositories. This approach restricts the searches and results to those databases that are Z39.50 compatible. The results users see from searching multiple repositories through a single interface and those achieved when searching repositories in their native interfaces may differ significantly due to the following factors:
- How the server interprets the query from the client. This is particularly clear when using multiple keywords. Some databases will search a keyword string as a phrase; some will automatically add the Boolean operator “and”; and some will automatically add the Boolean operator “or.”
- How a specific person, place, event, object, idea, or concept is expressed in one database may not be how it is expressed in another (the vocabulary issue).
- How results are displayed in various metasearch engines: in the order they were retrieved; by the database in which they were found; sorted by date; or integrated and ranked by computer-determined relevancy. The greater the number of results, the more advantage there is in sorting by relevancy and date.27
The limitations of Z39.50 have encouraged the development of alternative solutions to federated searching to improve results. One approach is the Metasearch XML Gateway (MXG), which allows queries in an XML format from a client to generate result sets from a server in an XML format.28 Another approach used by metasearch engines when the database does not support Z39.50 is relying on HTTP parsing or “screen scraping.” In this approach, the search retrieves an HTML page that is parsed and submitted to the user as a set of search results. Unfortunately, this approach requires a high level of maintenance, as the target databases change continually and the level of accuracy in retrieving content varies from one database to another.
Table 3. Methods for Gathering, Aggregating, and Making Metadata Available
| Method | Description | Examples |
|---|---|---|
| Batch processing of contributed data | A contributing institution/data provider makes its metadata records available in a standard format for batch loading/ingest by a service provider. |
|
| Real-time access to data via web services or linked-data APIs | Data is made available in real time via web APIs (application programming). The data is provided in documented standardized serializations (e.g., JSON, JSON-LD, XML, linked open data), and can be used/reused in local applications, combined with local search results, etc. |
|
| Harvesting | Records expressed in a standard metadata schema (e.g., Dublin Core) are made available by data providers on specially configured servers. The records are harvested, batch processed, and made available by service providers from a single database or index. The service provider preprocesses the contributed data and stores it locally before it is made available for searching by users. In order for records to be added or updated, data providers must post fresh metadata records, and service providers must reharvest, batch process, and integrate the new and updated records into the union catalog. |
|
| Screen scraping | The extraction of display data (usually unstructured) and hidden embedded data from web pages. |
|
| Metasearch of distributed metadata records | Diverse databases on different platforms and often with different metadata schemas are searched in real time via one or more protocols (e.g. Z39.50, screen scraping, APIs). The service provider does not preprocess or store data but rather processes data only when a user launches a search. Search results are usually displayed target-by-target, as integrating retrieved records from each different database into a single ranked result set is difficult and time consuming. |
The key to improvement may lie in implementing multiple protocols rather than a single protocol. Currently, some vendors29 are combining Z39.50 and XML gateway techniques to increase the number of “targets” or servers that can be queried.
The Summon discovery tool, developed by Serials Solutions, a subsidiary of Proquest, purports to be an approach that goes beyond Z39.50.30 Summon does not link out to other databases to retrieve content, but rather ingests metadata and full texts from a variety of resource producers into a single repository. Jeffrey Daniels and Patrick Roth of Grand Valley State University, in Allendale, Michigan, described their implementation of Summon and the mapping between catalog records for books and the Summon fields.31 Unlike Dublin Core, the Summon metadata model provides far more granular access, reflecting the wide variety of publication types and metadata standards of the resources in the federated repository.32
Metadata Harvesting
Searching across multiple heterogeneous databases in real time causes significant performance issues; retrieval of search results is so slow that users are likely to lose patience and abandon their queries. Another approach is to create single repositories by “harvesting” metadata records from various resources and putting them into a single database or index. The challenge is how to ensure that the harvested records “play well” and are understandable in their new environment while maintaining their original integrity.
Within a single community, union catalogs can be created where records from different institutions can be centrally maintained and searched with a single interface. This is possible when the community shares the same rules of description and access as well as the same protocol for encoding the information. OCLC, the major bibliographic utility in North America, provides what is essentially a huge union catalog representing the holdings of many libraries around the world.33 Local union catalogs, on the other hand, are typically based on geography and/or a shared system; for example, the University of California and California State University systems each maintain their own union catalogs. Interoperability tends to be high in such shared systems because of the shared rules for creating the catalog records.34
To simplify the process for federating diverse resources and to preserve interoperability, the OAI-PMH adopted Simple Dublin Core as its minimum standard. Data providers who expose their metadata for harvesting are required to provide records in Simple Dublin Core expressed in XML and to use UTF-8 character codes in addition to any other metadata formats they expose. The data providers may expose all of their metadata records or selected sets of records for harvesting. Data services operating downstream of the harvesting source may enhance the value of the metadata in the form of added fields (for example, additional audience or grade-level metadata elements for educational resources). Data services have the potential to provide a richer contextual environment where users can find related and relevant content. OAI harvesters request the data through HTTP. Repositories using a richer metadata standard than Dublin Core need to map their content to Simple Dublin Core before exposing it for OAI harvesting. Part of the challenge of creating a crosswalk is understandings the pros and cons of mapping all of the content from the larger metadata set or deciding which subset of that content should be mapped.
The limitations of mapping between metadata standards have been outlined above. Bruce and Hillmann established a set of criteria for measuring the quality of metadata records harvested and aggregated into a larger collection. The criteria may be divided into two parts, one that evaluates the metadata content as a whole for completeness, currency, accuracy, and provenance; and another that evaluates the technical solutions: conformance (or lack thereof) of the metadata sets and application profiles, and consistency and coherence of the metadata standards.35 In the context of harvesting data for reuse, Dushay and Hillmann have identified four categories of metadata problems in the second criterion for quality:
- missing data: data that the metadata contributor considered unnecessary to expose for harvesting;
- incorrect data: data entered in the wrong metadata element or encoded improperly;
- confusing data: data that uses inconsistent formatting or punctuation;
- insufficient data: incomplete data concerning the encoding schemes or vocabularies that were used.36
A recent study evaluating the quality of harvested metadata found that while collections of metadata records from a single institution did not vary significantly in terms of the criteria above, the amount of “variance” increased dramatically when the aggregations of harvested metadata came from many different institutions.37
Roy Tennant echoes the argument that this problem may be largely due to mapping richer metadata records to Simple Dublin Core. He suggests that both data providers and service providers consider exposing and harvesting metadata that is expressed in schemas that are richer than Simple Dublin Core. He argues that the metadata harvested should be as granular as possible and that the service provider should transform and normalize content such as date information, which can be expressed in a wide variety of encoding schemes (or following no scheme or standard at all).38 This approach creates a single silo for searching rather than decentralized or distributed searching. In order to facilitate searching, an extra “layer” is added to the repository to manage the mapping and searching of heterogeneous metadata standards within a single repository. Godby, Young, and Childress suggested a model for creating a repository of metadata crosswalks that could be exploited by OAI harvesters. Documentation about the mapping would be associated with the standard used by data providers and the standard used by the service providers encoded in the Metadata Encoding and Transmission Standard.39 This would provide a mechanism that supports repositories with OAI-harvested metadata in dealing with transforming metadata. As of this writing, it remains to be seen whether metadata harvesting (and indeed metasearching as it is currently understood) will eventually be made obsolete as a result of the widespread adoption of the Semantic Web of linked open data.
CASE STUDIES
Each instance of conversion, transformation, metasearching, or harvesting brings its own unique set of issues. Below are examples of projects that illustrate the complexities and pitfalls of creating crosswalks in order to transfer data to a new schema or to support cross-domain searching.
Case Study 1: Repurposing Metadata—ONIX and MARC21/RDA
In 2001 a task force was created by the Cataloging and Classification: Access and Description Committee, an Association for Library Collections and Technical Services committee of the American Library Association, to review a standard developed by the publishing industry and to evaluate the usefulness of data in its records that could potentially enhance the bibliographic records used by libraries. The task force reviewed and categorized the ONIX (Online Information Exchange) metadata element set and found that fields developed to help bookstores increase sales also had value for library users.40 In response, the Library of Congress directed the Bibliographic Enrichment Advisory Team to repurpose three categories of data supplied by the publishers: table of contents, descriptions, and sample texts. The publisher-generated content is saved on servers at the Library of Congress and appears in the bibliographic records as links (see fig. 1).41 Although the metadata was originally created to manage books as business assets and to provide information to bookstores that would help increase book sales, the same metadata (accessed by a hyperlink) has been incorporated into the bibliographic records used by libraries to provide additional information for users so that they can more easily evaluate the particular item.
In 2006 the Joint Steering Committee for the Development of RDA proposed a new crosswalk that would map RDA and ONIX.42 The International Federation of Library Associations and Institutions Cataloging Section developed a RDA-ONIX mapping of only two areas: content form and media type.43 The mapping is a moving target, since in the meantime not only has the library world transitioned from AACR2rev to RDA and from MARC to other metadata schemes (notably MODS, though as of this writing MARC remains the prevailing metadata schema for library production systems), but ONIX has moved to version 3.0. Carol Jean Godby at OCLC has written a report with a crosswalk that maps ONIX 3.0 to MARC21.44 This replaces earlier crosswalks used by OCLC to incorporate data from ONIX records to enhance bibliographic records. Godby quotes Karen Coyle to the effect that the migration to RDA as the new data content standard and the use of identifiers rather than descriptive strings should make it easier to automate the repurposing of data from ONIX records for incorporation into library catalog records.45
Figure 1. MARC Record (Brief Display) with Embedded Links to ONIX Metadata (Publisher Description and Table of Contents)
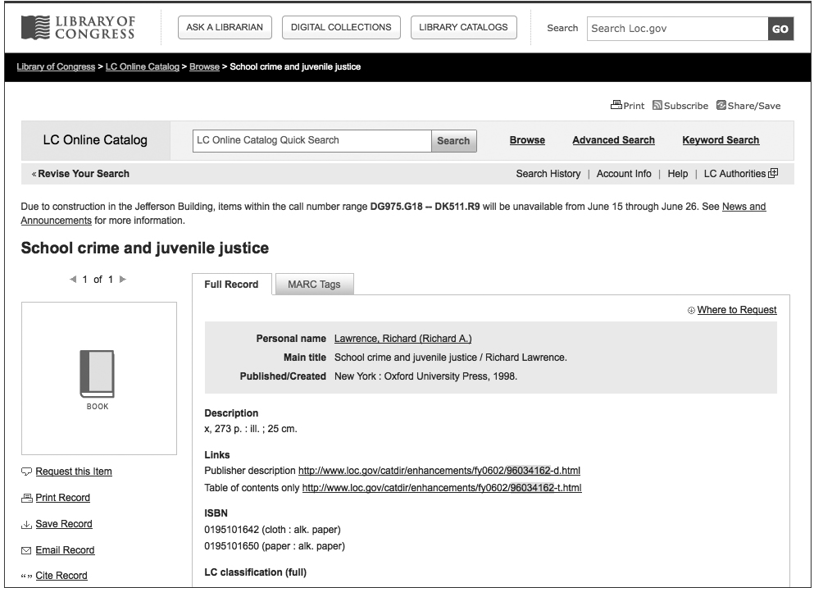
In an interesting side note, Godby recognizes that the complexity of the XML structure for both standards makes it difficult to visualize the relationship between them in a standard table. Instead, she compares separate sections of the records rather than creating one long table. At the end of the report, she addresses the possibility that future implementation of RDA may provide some improvement in the ability to share data between standards.46 The takeaway is that no crosswalk is static. As standards change, the mappings between and among them must be continually updated.
Case Study 2: Developing Standards for the Cultural Heritage Community—CIMI, VRA Core 4.0?
Compared to the library community, the cultural heritage community is a latecomer to creating data standards to share content and to facilitate search and retrieval. An early project, the Consortium for the Computer Interchange of Museum Information (CIMI), was founded in 1990 to promote the creation of standards for sharing cultural information electronically.47 In 1998 CIMI designed a project to map museum data to Simple Dublin Core.48 The main goal of CIMI was to test the efficacy of automating the conversion of nonstandard legacy museum data to a “web-friendly” standard—that is, to Dublin Core—with as little human intervention as possible.
The CIMI test bed was successful in that it demonstrated the pitfalls of migrating between two different sets of metadata whose granularity and purposes differ so greatly. It is a good example of how difficult it is to map data that resides in very specific and narrowly defined fields to a schema that lacks the same depth or coverage. During the transformation process, information from existing museum records ended up being entered into inappropriate metadata elements or duplicated in two separate elements. For example, since museum systems traditionally recorded subject information as a single field without subfield coding, a subject string like “baroque cathedral” was duplicated in both the Dublin Core coverage.temporal metadata element and the coverage.topical element. There are two ways of looking at this dilemma: there is no program that is sufficiently sophisticated to deconstruct a topical string into its component parts (temporal, topical, and geographical) for migrating to the appropriate separate element; or, that migrating to separate elements was not appropriate and duplicating the information was unnecessary.
In the mid-1990s, paralleling the work of the CIMI project, the visual resources community—led by the Visual Resources Association (VRA), the leading organization in North America for visual resources information professionals—developed a schema for describing image collections. After reviewing the elements of description employed by more than sixty institutions, the community developed a core group of thirteen elements based on the Categories for the Description of Works of Art (CDWA).49 The VRA schema has five metadata elements that describe the content of an image and five elements that describe a digital or other surrogate. The Library of Congress hosts the VRA Core 4.0 standard, which is expressed as an XML schema.50 Mapping between VRA Core and Dublin Core is fairly straightforward, so long as the underlying data has been consistently recorded. The cultural heritage organizations and projects that use the CONTENTdm collection management system for their digital collections have the choice of using Dublin Core or VRA Core as their metadata standard. Dublin Core has a longer history with library projects than VRA Core and is a standard with which many libraries have more familiarity. One challenge is that Dublin Core purportedly follows the principle that each record should describe either the original or a digital surrogate, but not both.51 In reality, it is not unusual for institutions and projects to violate this principle for the sake of expediency: many libraries lack a separate preservation database or digital asset management system in which they can record details concerning the digital surrogate they must manage. In contrast, a VRA Core record—like many records in photo archives and other image repositories—has a “hybrid” structure that supports the description of both the original work of art, architecture, or material culture and its visual surrogates, digital or otherwise. The VRA Core schema has the added advantage of describing the cultural aspects of the object; for example, culturalContext and creatorRole are elements in the VRA Core schema; Dublin Core could never accommodate this kind of specificity.
Providing a metadata structure to record categories of content (a “data structure standard” according to our typology of data standards; see table 1 in chapter 1) is not the same as providing the rules to follow in populating the individual metadata categories (“data content standard,” according to our typology). Cataloging Cultural Objects (CCO)52 is a data content standard establishing the rules for cataloging cultural materials and their visual (including digital) surrogates for the cultural heritage community. CCO was conceived in 1999 and was published in the summer of 2006 by the American Library Association. The need of a transmission standard to support data using CCO led to the creation of the CDWA Lite XML schema.53
Case Study 3: Preparing Metadata Records in the CDWA Lite XML Schema for Harvesting by Artstor
Experience from the CIMI experiment and other projects showed that Dublin Core and the Metadata Object Description Schema (MODS) were not sufficient to handle the kinds of information needed by the cultural heritage community. The Getty Trust proposed another approach that would enhance the process of making the legacy content found in library and museum collections management systems accessible to the public.
In 2005 the Getty Trust partnered with Artstor to test the efficacy of harvesting data from legacy databases for inclusion in the Artstor Image Library. The Getty Museum and Getty Research Institute (the data providers) worked together with Artstor (the service provider) to develop an XML schema that could be used with the OAI protocol to harvest both data and images (known as “resources” in OAI parlance). The schema developed, CDWA Lite, is a subset of the huge CDWA element set expressed in XML. This XML schema is comprised of 22 of the more than 300 metadata elements included in the complete CDWA specification. The objective of the project was to offer museums and image repositories a less labor-intensive approach to sharing their content. In order to expedite the process, the schema was optimized to work with OAI-PMH, then, as now, the prevailing protocol for metadata harvesting.54
Two collections were chosen for the project: paintings on public display in the Getty Museum and historical tapestries in the photo archive of the Getty Research Institute. The working group determined that the museum records contained more information than was necessary or appropriate for sharing in a “union” repository like Artstor. Examples of information that was not considered appropriate for inclusion in the Artstor contribution included provenance, exhibition history, specific location information within the museum, and some metadata elements that contained administrative or confidential information (such as the price paid for an object). The group worked under the assumption that the URL embedded in the Artstor record that links to the web page and image(s) for a particular object on the Getty’s website would provide the user with more detailed information in the object’s own institutional context. Therefore, a subset of information elements was selected for the project. Fortunately, the Getty Museum uses a schema that maps to CDWA for the basis for their collection management system. The in-house content guidelines are similar to the CCO guidelines, but some of the data needed to be manipulated during the export process. For instance, the object-type element in the Getty Museum system uses the plural form (paintings, not painting) and therefore does not comply with the CCO standard. The project team members responsible for the metadata mapping determined which information to select for mapping and which information to exclude altogether.
Migrating the tapestry records from the Getty Research Institute was more complex, since the records were created in a proprietary database using a nonstandard, collection-specific schema. In this case the working group approached the mapping differently, choosing to map the nonstandard metadata records in their entirety to the CDWA Lite XML schema. As part of the conversion, the nonstandard diacritics in the photo archive databases had to be converted to Unicode UTF-8, which is required by the OAI protocol. Although content values were successfully migrated, the more than fifty-five elements in a Getty Research Institute tapestry record had to be “forced into” the twenty-two CDWA Lite metadata elements. Once harvested, the data and the images were converted to the Artstor standard, which is based on CDWA Lite.
The experience that the Getty Museum and Getty Research Institute gained in crosswalking and preparing legacy metadata records for harvesting and reuse led to the realization that it would be desirable to have a single, simple schema to facilitate sharing metadata relating to cultural heritage objects from museums, including those not dedicated to the fine arts. The decision was made to modify the CDWA Lite schema for harvesting metadata with as little loss of information as possible and to improve the mapping between the various metadata standards used by the cultural heritage communities.
Case Study 4: LIDO
The standards communities that had developed CDWA Lite, museumdat, SPECTRUM, and the CIDOC CRM worked collaboratively to create a new standard to support sharing content among the scientific, bibliographic, and cultural heritage communities. The result was an XML schema called Lightweight Information Describing Objects (LIDO).55 LIDO is not a substitute for more robust standards like CDWA or the CIDOC CRM but can serve as a common standard to map metadata from various repositories and as a harvesting standard to work with OAI-PMH.56 It contains fourteen groups of metadata elements, only three of which are required: object/work type, title/name, and record. A record has seven areas, four of which are descriptive and three of which are administrative. Like many current metadata standards, LIDO is expressed in XML, which supports structural data that bundles elements in order to create sets of related elements. The alphabetical list of LIDO elements57 is a combination of a data dictionary—where each element has its description, tags, and restrictions—and a crosswalk of the four main cultural heritage metadata standards to LIDO.
Who has implemented LIDO?58 An important example is Europeana,59 a federated repository of cultural heritage metadata records that numerous European repositories use to share their content through harvesting and ingestion activities. The Yale Center for British Art has also adopted the standard for the inclusion of its rich metadata in a discovery portal being developed there.60
Conclusion
The technological universe of crosswalks, mapping, federated searching over heterogeneous databases, and aggregating full-text resources and metadata sets into single repositories is rapidly changing. Crosswalks are still at the heart of supporting conversion projects and enabling the semantic interoperability that makes it possible to search across heterogeneous distributed databases. Inherently, there will always be limitations to crosswalks; there is rarely a one-to-one correspondence between metadata standards, even when one standard is a subset of another. Mapping the elements or fields of metadata systems is only one part of the picture. Crosswalks of controlled terms or thesauri will further enhance searchers’ ability to retrieve the most precise search results. As the number and size of online resources increases, the ability to refine searches and to use controlled vocabularies and thesauri both at the metadata creation stage and at the moment of searching will become increasingly important.
-
What determines the granularity or level of detail in any element will vary from standard to standard. In various systems, a single instance of metadata may be referred to as a field, a label, a tab, an identifier. Margaret St. Pierre and William P. LaPlant Jr., “Issues in Crosswalking, Content Metadata Standards” (white paper, National Information Standards Organization, Baltimore, 1998), http://www.niso.org/publications/white_papers/crosswalk/. ↩
-
A metadata standards crosswalk that includes many of the standards discussed here is available at http://www.getty.edu/research/publications/electronic_publications/intrometadata/crosswalks.html. ↩
-
See http://www.openarchives.org/. Of specific interest, under documents, is the documentation on the protocol for harvesting, a tutorial, and a link to the National Science Digital Library’s Metadata Primer. ↩
-
See http://www.dublincore.org/documents/usageguide/glossary.shtml#I. ↩
-
Ibid. Crosswalks can be expressed or coded for machines to automate the mapping between standards. ↩
-
See http://www.w3.org/RDF. ↩
-
Sherry L. Vellucci, “Metadata and Authority Control.” LRTS 44 (1) (January 2000): 33–43. ↩
-
See http://viaf.org/. ↩
-
Biligsaikhan Batjargal et al., “Linked Data Driven Dynamic Web Services for Providing Multilingual Access to Diverse Japanese Humanities Databases,” in DC-2103—Proceedings of the International Conference on Dublin Core and Metadata Applications, September 2–6, 2013, Lisbon, Portugal (Dublin Core Metadata Initiative, 2013), http://dcevents .dublincore.org/IntConf/dc-2013/paper/view/150/72. ↩
-
Jessica L. Milstead, “Cross-File Searching,” Searcher 7, no. 1 (May 1999): 44–55. ↩
-
For an introduction to SKOS, see Alistair Miles et al., “SKOS Core: Simple Knowledge Organization for the Web,” in DC-2005—Proceedings of the International Conference on Dublin Core and Metadata Applications, September 12–15, 2005, Madrid, Spain (Dublin Core Metadata Initiative, 2005), http://dcpapers.dublincore.org/pubs/article/view/798. ↩
-
Naomi Dushay and Diane Hillmann, “Analyzing Metadata for Effective Use and Re-use,” in DC-2003—Proceedings of the DCMI International Conference on Dublin Core and Metadata Applications, September 28–October 2, 2003, Seattle, Washington (Dublin Core Metadata Initiative, 2003), http://dcpapers.dublincore.org/pubs/article/view/744. ↩
-
St. Pierre and LaPlant, “Issues in Crosswalking.” ↩
-
CDWA is a standard for cataloging cultural objects maintained by the J. Paul Getty Trust and the College Art Association; see http://www.getty.edu/research/publications/electronic_publications/cdwa/. ↩
-
Martin Kurth, David Ruddy, and Nathan Rupp, “Repurposing MARC Metadata: Using Digital Project Experience to Develop a Metadata Management Design,” Library High Tech 22, no. 2 (2004): 153–65. ↩
-
Numerous presentations and publications explain the differences between the two standards. The Library of Congress has created an excellent crosswalk between MARC and RDA at http://www.loc.gov/catdir/cpso/RDAtest/training2word9.doc. ↩
-
See http://www.getty.edu/research/publications/electronic_publications/intrometadata/crosswalks.html. ↩
-
For other examples of crosswalk issues, see “Challenges and Issues with Metadata Crosswalks,” Online Libraries & Microcomputers (April 2002). ↩
-
For a fuller history of the development of the standard, see Clifford A. Lynch, “The Z39.50 Retrieval Standard—Part 1: A Strategic View of its Past, Present and Future,” D-Lib 3, no. 4 (April 1997), http://www.dlib.org/dlib/april97/04lynch.html. ↩
-
Roy Tennant, “Interoperability: The Holy Grail,” Library Journal, July 1, 1998, available at http://roytennant.com/column/?fetch=data/95.xml. Tennant argued that interoperability was the holy grail; to others it is Z39.50 and its successor, ZING (Z39.50 International: Next Generation). ZING is no longer a standard maintained by the Library of Congress. It has been folded into SRU (Search/Retrieval via URL); see http://www.loc.gov/standards/sru/. ↩
-
Judy Luther, “Trumping Google? Metasearching Promise,” Library Journal, October 1 2003, 36–39. ↩
-
Lynn Lampert and Kathy Dabbour, “Librarian Perspectives on Teaching Metasearch and Federated Search Technologies,” Internet Reference Services Quarterly 12, nos. 3–4 (September 2007): 253–78. ↩
-
Terence K. Huwe, “New Search Tools for Multidisciplinary Digital Libraries,” Online 23, no. 2 (March 1999): 67–70. ↩
-
The protocol is an NISO standard, http://www.niso.org/standards/resources/Z39.50_Resources, which is maintained by the Library of Congress; see http://www.loc.gov/z3950/agency and the International Organization for Standardization standard, http://www.iso .org/iso/en/CatalogueDetailPage.CatalogueDetail?CSNUMBER=27446. A good history of Z39.50 was published in William E. Moen, “Interoperability and Z39.50 Profiles: The Bath and US Profiles for Library Applications” (2001) in From Catalog to Gateway: Charting a Course to Future Access, ed. Bill Sleeman and Pamela Bluh (Chicago: Association for Library Collections and Technical Services, American Library Association, 2005), 113–20. ↩
-
Tamar Sadeh. “The Challenge of Metasearching,” New World Library 105, nos. 1198–1199 (2004): 104–12. ↩
-
NISO Metasearch Initiative, Standards Committee BC, Task Group 3, “Metasearch XML Gateway Implementers Guide, Version 1.0” (Bethesda, MD: National Information Standards Organization, 2006), http://www.niso.org/publications/rp/RP-2006-02.pdf. ↩
-
Ex Libris’s MetaLib product and Endeavor’s now-defunct Encompass system adopted this approach. ↩
-
See http://www.dc4.proquest.com/en-US/products/brands/pl_ss.shtml. ↩
-
Jeffrey Daniels and Patrick Roth, “Incorporating Millennium Catalog Records into Serials Solutions’ Summon,” Technical Services Quarterly 29, no. 3 (2012), 193–99. ↩
-
See http://api.summon.serialssolutions.com/help/api/search/fields. ↩
-
See “What Is WorldCat?” at http://www.worldcat.org/whatis/. ↩
-
Interoperability issues caused by changes to the standards still remain; see number 6 in the list of common misalignments above. ↩
-
Thomas R. Bruce and Diane I. Hillmann, “The Continuum of Metadata Quality: Defining, Expressing, Exploiting,” in Metadata in Practice, ed. Diane Hillmann and Elaine L. Westbrooks (Chicago: American Library Association, 2004), 238–56. ↩
-
Dushay and Hillmann, “Analyzing Metadata for Effective Use and Reuse.” ↩
-
Sarah L. Shreeves et al., “Is ‘Quality’ Metadata ‘Shareable’ Metadata? The Implications of Local Metadata Practices for Federated Collections” (paper presented at the Twelfth National Conference of the Association of College and Research Libraries, Minneapolis, April 9, 2005), http://www.ala.org/acrl/sites/ala.org.acrl/files/content/conferences/pdf/shreeves05.pdf. ↩
-
Roy Tennant, “Bitter Harvest: Problems and Suggested Solutions for OAI-PMH Data and Service Providers,” last modified May 14, 2004, http://roytennant.com/bitter_harvest.html. ↩
-
Carol Jean Godby, Jeffrey A. Young, and Eric Childress, “A Repository of Metadata Crosswalks,” D-Lib 10, no. 12 (December 2004), http://www.dlib.org/dlib/december04/godby/12godby.html. ↩
-
The full report can be found at http://www.libraries.psu.edu/tas/jca/ccda/tf-onix1.html. The ONIX standard is available at http://www.editeur.org/. The crosswalk between ONIX and MARC21 can be found at http://www.loc.gov/marc/onix2marc.html. ↩
-
See http://www.loc.gov/catdir/beat/. The announcement of the ONIX project is available at http://www.loc.gov/catdir/beat/beat_report.1.2001.html. ↩
-
See http://www.ifla.org/files/assets/cataloguing/isbd/OtherDocumentation/ISBD2ROF Mapping v1_1.pdf. ↩
-
Carol Jean Godby, A Crosswalk from ONIX Version 3.0 for Books to MARC 21 (Dublin, OH: Online Computer Library Center; OCLC Research, 2012), http://www.oclc.org/content/dam/research/publications/library/2012/2012-04.pdf. The crosswalk is available at http://www.oclc.org/content/dam/research/publications/library/2012/2012-04a.xls. ↩
-
Godby, A Crosswalk, 11. ↩
-
Ibid., 37. ↩
-
The CIMI project ceased as of December 15, 2003. Some of the original documentation can still be found at http://old.cni.org/pub/CIMI/framework.html, and older documents are archived at http://web.archive.org/web/*/http://www.cni.org. ↩
-
The Dublin Core element set is NISO standard Z39.85: http://www.niso.org/apps/group_public/download.php/10256/Z39-85-2012_dublin_core.pdf. ↩
-
Murtha Baca and Patricia Harpring, Categories for the Description of Works of Art (Los Angeles: J. Paul Getty Trust; College Art Association, 2009), last modified March 2014, http://www.getty.edu/research/publications/electronic_publications/cdwa/. The CDWA is an exhaustive set of metadata elements that may be used to describe art objects. It is not the goal of CDWA to be a standard used in its entirety; rather, it is intended to serve as a framework or guidelines for creating and/or mapping descriptive metadata records for cultural objects. The CCO data content standard provides guidelines for creating the content to fill the elements set forth in CDWA. ↩
-
See http://vraweb.org/resources/cataloging-metadata-and-data-management/data-standards-faqs/. ↩
-
See http://dublincore.org/documents/usageguide/glossary.shtml; a new version is in the process of being revised at http://wiki.dublincore.org/index.php/Glossary. ↩
-
Documentation is available at http://cco.vrafoundation.org/index.php/aboutindex/. The standard is hosted by the Library of Congress: http://www.loc.gov/standards/vracore/. ↩
-
CDWA Lite: XML Schema Content for Contributing Records via the OAI Harvesting Protocol, version 1.1 (Los Angeles: J. Paul Getty Trust; Artstor, 2006), http://www.getty .edu/research/publications/electronic_publications/cdwa/cdwalite.pdf. ↩
-
See Karim B. Boughida, “CDWA Lite for Cataloguing Cultural Objects (CCO): A New XML Schema for the Cultural Heritage Community” in Humanities, Computers, and Cultural Heritage: Proceedings of the XVI International Conference of the Association for History and Computing, 14–17 September 2005 (Amsterdam: Royal Netherlands Academy of Arts and Sciences, 2005). ↩
-
Erin Coburn et al., LIDO—Lightweight Information Describing Objects, Version 1.0. (ICOM-CIDOC, November 2010), http://www.lido-schema.org/schema/v1.0 /lido-v1.0-specification.pdf. ↩
-
See http://network.icom.museum/cidoc/working-groups/data-harvesting-and-interchange/what-is-lido/. ↩
-
Coburn et al., LIDO, 27. ↩
-
A select list of implementations of LIDO is available at http://network.icom.museum/cidoc/working-groups/data-harvesting-and-interchange/lido-community/use-of-lido/. ↩
-
See http://www.europeana.eu. ↩
-
See http://britishart.yale.edu/sites/default/files/files/2011_GS_CI_Implementing_Lightweight_Information_Describing_Objects_LIDO_at_the_Yale_Center_for_British_Art.pdf. ↩