Metadata, literally “data about data,” is today a widely used, yet frequently underspecified term that is understood in different ways by the diverse professional communities that design, create, describe, preserve, and use information systems and resources. Until the mid-1990s, metadata was a term used primarily by communities involved with the management and interoperability of geospatial data and with data management and systems design and maintenance in general. For these communities, the term referred to a suite of industry or disciplinary standards as well as additional internal and external documentation and other data necessary for the identification, representation, interoperability, technical management, performance, and use of data contained in an information system.
As a construct, however, metadata has been around for as long as humans have been organizing information, albeit transparently in many cases. Today, we create and interact with it in increasingly digital and overt ways. For more than a century, and particularly since the first developments of national and international descriptive standards, the creation and management of metadata was primarily the responsibility of information professionals engaged in cataloging, classification, and indexing; but as more information resources were created or put on line and networked—especially via the web—by the general public, metadata considerations were no longer solely the province of information professionals. Although metadata is arguably a less familiar term among creators and consumers of networked digital content who are not information professionals per se, those same individuals are increasingly adept at creating, exploiting, and assessing user-contributed metadata such as title, description, and keyword tags for web pages; terms from so-called folksonomies; and social bookmarks. Schoolchildren, college students, and adult learners are taught in information literacy programs to look for metadata such as provenance and date information in order to ascertain the authoritativeness of information they retrieve on line. Others are using tag clouds and tag graphs to visualize the terminology and structures being used in metadata for selective information resources. Thus it has become more important than ever that not only information professionals but also other creators and users of digital content understand the critical roles and potential uses of different types of metadata in ensuring accessible, authoritative, interoperable, scalable, and preservable cultural heritage information and record-keeping systems.
Perhaps a more useful, “big picture” way of thinking about metadata is as the sum total of what one can say at a given moment about any information object at any level of aggregation.1 In this context, an information object is anything that can be addressed and manipulated as a discrete entity by a human being or an information system. The object may be a single item, an aggregate of many items, or an entire database or record-keeping system. Indeed, in any given instance one can expect to find metadata relevant to any information object existing simultaneously at the item, aggregate, and system levels.
In general, all information objects, regardless of the physical or intellectual form they take, have three features—content, context, and structure—all of which can and should be reflected through metadata:
- Content relates to what the object contains or is about and is intrinsic to an information object.
- Context indicates the who, what, why, where, and how aspects associated with the object’s creation and subsequent life and is extrinsic to an information object.
- Structure relates to the formal set of associations within or among individual information objects and can be intrinsic, extrinsic, or both.
All objects carry with them certain metadata that innately results from the circumstances of their creation, management, and use. However, cultural heritage information professionals such as museum registrars, library catalogers, and archival processors often apply the term metadata to the value-added information they create to arrange, describe, track, and otherwise enhance access to information objects and the physical items and collections related to those objects. Such metadata is frequently governed by community-developed and community-fostered standards and best practices in order to ensure quality, consistency, and interoperability. Our Typology of Data Standards (table 1) organizes these standards into categories and provides examples of each. Markup languages such as HTML and XML and a variety of schemas and metadata formats provide standardized ways to structure and express these standards for machine processing, publication, and implementation.
Table 1. A Typology of Data Standards
| Type | Examples |
|---|---|
| Data structure standards (metadata element sets, schemas). These are “categories” or “containers” of data that make up a record or other information object. | MARC (Machine-Readable Cataloging) Format, Encoded Archival Description (EAD), BIBFRAME (Bibliographic Framework), Dublin Core Metadata Element Set, Categories for the Description of Works of Art, VRA Core |
| Data value standards (controlled vocabularies, thesauri, controlled lists). These are the terms, names, and other values that are used to populate data structure standards or metadata element sets. | Library of Congress Subject Headings, Name Authority File, and Thesaurus for Graphic Materials; Getty Art & Architecture Thesaurus, Union List of Artist Names (ULAN), and Thesaurus of Geographic Names; ICONCLASS; Medical Subject Headings |
| Data content standards (cataloging rules and codes). These are guidelines for the format and syntax of the data values that are used to populate metadata elements. | Anglo-American Cataloguing Rules, Resource Description and Access, International Standard Bibliographic Description, Cataloging Cultural Objects, Describing Archives: A Content Standard |
| Data format/technical interchange standards (metadata standards expressed in machine-readable form). This type of standard is often a manifestation of a particular data structure standard (see above), encoded or marked up for machine processing. | Resource Description Framework, MARC21, MARCXML, EAD XML DTD, METS, BIBFRAME, LIDO XML, Simple Dublin Core XML, Qualified Dublin Core XML, VRA Core 4.0 XML |
| Note: This table is based on the typology of data standards articulated by Karim Boughida in his article “CDWA Lite for Cataloging Cultural Objects (CCO): A New XML Schema for the Cultural Heritage Community” in Humanities, Computers, and Cultural Heritage: Proceedings of the XVI International Conference of the Association for History and Computing, 14–17 September 2005 (Amsterdam: Royal Netherlands Academy of Arts and Sciences, 2005), http://www.dans.knaw.nl/nl/over/organisatie-beleid/publicaties/DANShumanitiescomputersandculturalheritageUK.pdf. | |
Library metadata development has been first and foremost about providing intellectual and physical access to collection materials. Library metadata includes indexes, abstracts, and bibliographic records created according to cataloging rules (i.e., data content standards, according to our typology) such as the Anglo-American Cataloguing Rules (AACR) and more recently Resource Description and Access (RDA) and data structure standards such as the MARC (Machine-Readable Cataloging) and BIBFRAME (Bibliographic Framework) formats, in combination with data value standards such as the Library of Congress Subject Headings (LCSH) or the Getty’s Art & Architecture Thesaurus (AAT). Such bibliographic metadata has been systematically and cooperatively created and shared since the 1960s and made available to repositories and users through automated systems such as bibliographic utilities, online public access catalogs (OPACs), and commercially available databases. Today this type of metadata is created not only by humans but also in a variety of automated ways such as metadata mining, metadata harvesting, and web crawling.
Automation of metadata will inevitably continue to expand with the evolution and increased implementation of the Resource Description Framework (RDF), linked open data, and the Semantic Web, which are discussed later in this book.
A large component of archival and museum metadata creation activities has traditionally been focused on context. Elucidating and preserving context is what assists with identifying and preserving the evidential value of records and artifacts in and over time; it is what facilitates the authentication of those objects, and it is what assists researchers with their analysis and interpretation. Archival and manuscript metadata includes the products of value-added archival description such as finding aids, catalog records, and indexes. However, it also includes descriptive documentation generated in the course of creating, managing, preserving, using, and reusing both born-digital and digitized archival materials. Archival data structure standards that have been developed in the past three decades include the MARC Archival and Manuscripts Control (AMC) format, published by the Library of Congress in 1984 (now integrated into the MARC21 format for bibliographic description); the suite of international descriptive standards anchored by the General International Standard Archival Description (ISAD [G]), first published by the International Council on Archives in 1994, that provide the basis for various national descriptive standards used around the world; Encoded Archival Description (EAD), adopted as a standard by the Society of American Archivists in 1999, and its companion data content standard, Describing Archives: A Content Standard (DACS), first published in 2004. The Metadata Encoding and Transmission Standard (METS), developed by the Digital Library Federation and maintained by the Library of Congress, is often used for encoding descriptive, administrative, and structural metadata and digital surrogates at the item level for objects such as digitized photographs, maps, and correspondence from the collections described by finding aids and other collection or group-level metadata records.
Many repositories make standardized descriptive metadata for library and archival collections available on line through resources such as WorldCat, the Digital Public Library of America, and ArchiveGrid.
Consensus and collaboration were slower to build in the museum community, where the benefits of standardization of description, such as shared cataloging and exchange of descriptive data, were less readily apparent until relatively recently. Since the late 1990s tools such as Categories for the Description of Works of Art (CDWA), the CIDOC Conceptual Reference Model (CRM), Cataloging Cultural Objects: A Guide to Describing Cultural Works and Their Images (CCO), the LIDO (Lightweight Information Describing Objects) XML schema, and more generic standards such as Dublin Core and METS have been considered and implemented by museums.
Although it would seem to be a desirable goal to integrate materials of different types that are related by provenance or subject but distributed across the repositories of museums, archives, and libraries, initiatives such as Museums and the Online Archive of California (MOAC) have met with limited success. As MOAC and the mid-1980s development of the now-defunct MARC AMC format have demonstrated, the distinctiveness of the various professional and object-based approaches (e.g., widely differing notions of provenance and collectivity as well as of structure), different institutional cultures, and divergent cultural approaches (e.g., those exemplified in indigenous protocols for archival and library materials) have left many professionals, and the communities they represent, feeling that their practices and needs have been shoehorned into structures that were developed by another community with quite different epistemologies, practices, and users. As enunciated in principle 6 of “Practical Principles for Metadata Creation and Maintenance,” there is no single metadata standard or set of standards that is adequate for describing all types of collections and materials. Selection of the most appropriate suite of metadata standards and tools—and creation of clean, consistent metadata according to those standards—will not only enable good descriptions of specific collection materials, but will also make it possible to map metadata created according to different community-specific standards, thus furthering the goal of interoperability discussed in subsequent chapters of this book.
An emphasis on the structure of information objects in metadata development by the library, archives, and museum communities has perhaps been less overt. However, structure has always been important in information organization and representation, even before computerization. Documentary and publication forms have evolved into industry standards and societal norms and have become almost transparent information management tools. For example, when users access a birth certificate they can predict its likely structure and content. When academics use a scholarly monograph, they understand intuitively that it will be organized with a table of contents, chapter headings, and an index. Archivists use the physical structure of their finding aids to provide cues to researchers about the structural relationships between different parts of a record series or manuscript collection. Archival description also exploits the hierarchical arrangement of records according to the bureaucratic structures, business practices, and personal systems of organization of the creators of those records. However, in recent years there has been increasing criticism that collection-level, hierarchical metadata as exemplified in archival finding aids, while valuable for retaining context and original order, represents an oversimplified view of the actual complexities of records-creation processes and provenance, privileges the scholarly user of the archive (and those who are familiar with the structure and function of archival finding aids) while leaving the non-expert user baffled, and unnecessarily perpetuates a paper-based descriptive paradigm.2 In the online world, multiple descriptive relationships between objects can be supported simultaneously, and some of these, especially when used in addition to user-contributed metadata, may support new types of users and uses in an environment that is not mediated by a reference archivist. While concerned about reducing the amount of “overhead” involved in detailed metadata creation, archives and other collecting institutions are simultaneously exploring more granular methods of description, e.g., exploiting item-level metadata for digitized objects so that users can search for specific items, navigate through a collection “bottom up” as well as “top down,” and collate related collection materials through lateral searching across collections and repositories.
The role of structure in creating and exploiting machine-readable metadata has been growing as computer-processing capabilities become increasingly powerful and sophisticated. Information communities are aware that the more highly structured an information object is, the more that structure can be exploited for searching, manipulating, and interrelating with other information objects. Capturing, documenting, and enforcing that structure, however, can only occur if supported by specific types of metadata. In short, in an environment where a user can gain unmediated access to information objects over a network, metadata
- certifies the authenticity and degree of completeness of the content;
- establishes and documents the context of the content;
- identifies and exploits the structural relationships that exist within and between information objects;
- provides a range of intellectual access points for an increasingly diverse range of users; and
- presents some of the information that an information professional might have provided in a traditional, in-person reference or research setting.
But there is more to metadata than description and resource discovery. A more inclusive conceptualization of metadata is needed as we consider the range of activities that may be incorporated into digital information systems. Repositories also create metadata relating to the administration, accessioning, preservation, and use of collections. Acquisition records, exhibition catalogs, licensing agreements, and educational metadata are all examples of these other kinds of metadata and data. Integrated information resources such as virtual museums, digital libraries, and archival information systems include digital versions of actual collection content (sometimes referred to as digital surrogates) as well as descriptions of that content (i.e., descriptive metadata, in a variety of formats). Incorporating other types of metadata into such resources reaffirms the importance of metadata in administering collections and maintaining their intellectual integrity both in and over time. Paul Conway alluded to this capability of metadata when he discussed the impact of digitization on preservation: “The digital world transforms traditional preservation concepts from protecting the physical integrity of the object to specifying the creation and maintenance of the object whose intellectual integrity is its primary characteristic.”3
When applied outside the original repository, the term metadata acquires an even broader scope. An Internet resource provider might use metadata to refer to information that is encoded in HTML meta tags for the purposes of making a website easier to find. Individuals who are digitizing images might think of metadata as the information they enter into a header field for the digital file to record information about the image file, the imaging process, and image rights. A social science data archivist might use the term to refer to the systems and research documentation necessary to run and interpret a magnetic tape containing raw research data. A digital records archivist might use the term to refer to all the contextual, processing, preservation, and use information needed to identify and document the scope, authenticity, and integrity of an active or archival record in an electronic record-keeping or archival preservation system. Metadata is crucial in personal information management and digital archiving and for ensuring effective information retrieval and accountability in record- keeping—something that is becoming increasingly important with the rise of electronic commerce and the use of digital content and tools by governments. In all these diverse interpretations, metadata not only identifies and describes an information object; it also documents how that object behaves, its function and use, its relationship to other information objects, and how it should be and has been managed over time.
As this discussion suggests, theory and practices vary considerably due to the differing professional and cultural missions of museums, archives, libraries, and other information and record-keeping communities. Information professionals have a bewildering array of metadata standards and approaches from which to choose. Many highly detailed metadata standards have been developed by individual communities—e.g., MARC, BIBFRAME, EAD, LIDO, the Australian Recordkeeping Metadata Schema, and some of the standards for geographic information systems—that attempt to articulate their mission-specific differences as well as to facilitate mapping between common data elements. If used appropriately and to their fullest extent, these standards have the potential to create extremely rich metadata that provides detailed documentation of record-keeping creation and use in situations in which such activities may be challenged or audited for their comprehensiveness and accuracy.4 Creation and ongoing maintenance of such metadata, however, is complex, time consuming, and resource intensive and may only be justifiable when there is a legal mandate or other risk-management incentive, or when it is anticipated that the content and metadata may be reused or exploited in previously unanticipated ways, such as in digital asset management systems. By contrast, the Dublin Core Metadata Element Set (DCMES) identifies a relatively small, generic set of metadata elements that can be used by any community, expert or nonexpert, to describe and search across a wide variety of information resources on the World Wide Web. Such metadata standards are necessary to ensure that different kinds of descriptive metadata are able to interoperate with one other and with metadata from non-bibliographic systems of the kind that the data management communities and information creators are generating. Relatively lean metadata records such as those created using the DCMES have the advantage of being cheaper to create and maintain, but they may need to be augmented by other types of metadata in order to address the needs of specific user communities and to adequately describe particular types of collection materials.5
User-created metadata, both individually contributed and crowd sourced, has been gathering momentum in a variety of venues on the web. Just as many members of the general public have participated in the development of web content, whether by blogging on Tumblr or by uploading photos onto Flickr or videos onto YouTube, they have also been creating, sharing, copying, and mapping metadata. Among the advantages of these developments is that individual web communities such as affinity groups or hobbyists may be able to create metadata that addresses their specific needs and vocabularies in ways that information professionals who apply metadata standards designed to cater to a wide range of audiences cannot. Individuals and particular communities may also be using this capacity to offer corrections to the existing metadata, to “talk back” to the record, or to suggest how an object should be interpreted. User-generated metadata is also a comparatively inexpensive way to augment existing metadata, with the cost and the sense of ownership shared among more parties than just those who create information repositories. The disadvantages of user-generated metadata relate to quality control (or lack thereof) and idiosyncrasies that can impede the trustworthiness of both metadata and the resource it describes and negatively affect interoperability between metadata and the resources it is intended to describe. Issues of interoperability are discussed in some detail in the third chapter of this book (“Metadata Matters”).
Categorizing Metadata
All of these perspectives on metadata should be considered in the development of networked digital information systems, but they lead to a very broad and often confusing conception. To understand this conception better, it is helpful to separate metadata into distinct categories—administrative, descriptive, preservation, technical, and use metadata—that reflect key aspects of metadata functionality. Table 2 defines each of these metadata categories and gives examples of common functions that each might perform in a digital information system.
Table 2. Different Categories of Metadata and Their Functions
| Category | Definition | Example |
|---|---|---|
| Administrative | Metadata used in managing and administering collections and information resources |
|
| Descriptive | Metadata used to identify, authenticate, and describe collections and related trusted information resources |
|
| Preservation | Metadata related to the preservation management of collections and information resources |
|
| Technical | Metadata related to how a system functions or metadata behaves |
|
| Use | Metadata related to the level and type of use of collections and information resources |
|
In addition to its different types and functions, metadata exhibits many different characteristics. Table 3 presents some key characteristics of metadata, with examples. Metadata creation and management have become a complex mix of manual and automatic processes and layers created by many different functions and individuals at different points during the life cycle of an information object. Effective and efficient metadata management is essential to ensure that the metadata we rely on to validate digital resources is itself trustworthy and that the large volume of metadata that potentially can accumulate throughout the life of a resource is subject to a summarization and disposition regime.6
Table 3. Attributes and Characteristics of Metadata
| Attribute | Characteristics | Examples |
| Source of metadata |
|
|
| External metadata relating to an original item or information object; this is generated after the object is first created or digitized, often by someone other than the original creator |
|
|
| Method of metadata creation | Automatic creation, capture, or inferencing of metadata |
|
| Manual creation of metadata by information specialists | Descriptive metadata such as catalog records, finding aids, and specialized indexes | |
| Manual or automatic creation of metadata during digitization processes | ||
| Individual user-contributed or crowd-sourced metadata | ||
| Nature of metadata | Nonexpert metadata created by persons who are not subject or community specialists or information professionals (e.g., the original creator of the information object or a folksonomist) |
|
| Expert metadata created by subject or community specialists and/or information professionals, often not the original creator of the information object |
|
|
| Structure | Structured metadata that conforms to a predictable standardized or proprietary structure | MARC, BIBFRAME, TEI, EAD, LIDO, local database formats |
| Unstructured metadata that does not conform to a predictable structure | Unstructured note fields and other free-text annotations | |
| Status | Static metadata that does not or should not change once it has been created | Technical information such as the date(s) of creation and modification of an information object, how it was created, file size |
| Dynamic metadata that may change with use, manipulation, or preservation of an information object |
|
|
| Long-term metadata necessary to ensure that the information object continues to be accessible and usable |
|
|
| Short-term metadata, mainly of a transactional nature | Interim location information | |
| Legacy metadata | Metadata created using an earlier system of metadata scheme | |
| Semantics | Controlled metadata that conforms to a standardized vocabulary or authority form and that follows standard content (i.e., cataloging) rules |
|
| Uncontrolled metadata that does not conform to any standardized vocabulary or authority form |
|
|
| Level | Collection-level or group-level metadata relating to collections or groupings of original items and/or information objects |
|
| Item-level or within-item-level metadata relating to individual items and/or information objects, often contained within collections |
|
Figure 1 illustrates the different phases through which information objects typically move during their life cycles in today’s digital environment.7 As they move through each phase, information objects acquire layers of metadata that can be associated with them in several ways.
Figure 1. The Life Cycle of an Information Object
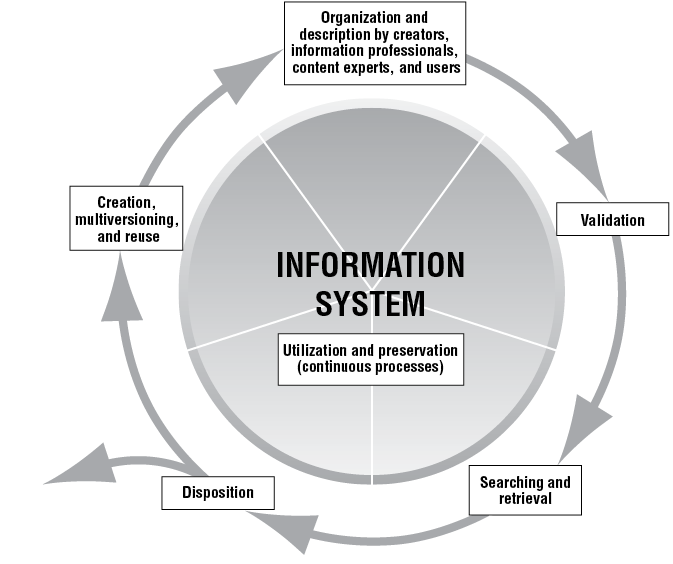
Different types of metadata can become associated with an information object by a variety of processes, both manual and automated. These layers of accrued metadata can be contained within the same “envelope” as the information object itself—for example, in the form of header information for an image file or through some form of metadata bundling (e.g., via METS) that packages structural, descriptive, administrative, and other metadata with an information object or digital surrogate and indicates the types of relationships among the various parts of complex information objects (e.g., a digital surrogate consisting of a series of images representing the pages in a book or an album of illustrations or the constituent parts of a decorative arts object such as a tea service). Metadata can also be attached to the information object through bidirectional pointers or hyperlinks, while the relationships between metadata and information objects—and among different aspects of metadata—can be documented by registering them with a metadata registry. However, in any instance in which it is critical that metadata and content coexist, it is highly recommended that the metadata become an integral part of the information object—that is, that it be “embedded” in the object and not stored or linked elsewhere.
As systems designers respond to the need to incorporate and manage metadata in information systems and to address how to ensure the ongoing viability of both information objects and their associated metadata through time, many additional mechanisms for associating metadata with information objects are likely to become available. Metadata registries and schema record-keeping systems are also more likely to develop as it becomes increasingly necessary to document schema evolution and to alert implementers to version changes.8
Primary Functions of Metadata
- Creation, multiversioning, reuse, and recontextualization of information objects. Objects enter a digital information system by being created digitally or by being converted into a digital format. Multiple versions of the same object may be created for preservation, research, exhibition, dissemination, or even product-development purposes. Some administrative and descriptive metadata may and indeed should be included by the creator or digitizer, especially if reuse is envisaged, such as in a digital asset management system.
- Organization and description. A primary function of metadata is the description and ordering of original objects or items in a repository or collection as well as of the information objects relating to the originals. Information objects are automatically or manually organized into the structure of the digital information system and may include descriptions generated by the original creator. Additional metadata may be created by information professionals through registration, cataloging, and indexing processes, or by others via folksonomies and other forms of user-contributed metadata.
- Validation. Users scrutinize metadata and other aspects of retrieved resources in order to ascertain the authoritativeness and trustworthiness of those resources.
- Search and retrieval. Good descriptive metadata is essential to users’ ability to find and retrieve relevant metadata and information objects. Information objects—both those that are locally stored and virtually distributed—are subject to search and retrieval by users, and information systems create and maintain metadata that tracks retrieval algorithms, user transactions, and system effectiveness in storage and retrieval.
- Utilization and preservation. In the digital realm, information objects may be subject to many different kinds of uses throughout their lives, during which they may also be reproduced and modified. Metadata related to user annotations, rights tracking, and version control may be created. Digital objects, especially those that are born digital, also need to be subject to a continuous preservation regime and undergo such processes as refreshing, migration, and integrity checking to ensure their continued availability and to document any changes that might have occurred to the information object during preservation processes.
- Disposition. Metadata is a key component in documenting the disposition (e.g., accessioning, deaccessioning) of original objects and items in a repository as well as of the information objects relating to those originals. Information objects that are inactive or no longer necessary may be discarded.
Some Little-Known Facts about Metadata
- Metadata does not have to be digital. Cultural heritage and information professionals have been creating metadata for as long as they have been managing collections. Increasingly, such metadata is being incorporated into digital information systems, but metadata can also be recorded in analog formats such as card catalogs, vertical files, and file labels.
- Metadata relates to more than the description of an object. While museum, archive, and library professionals may be most familiar with the term in association with description or cataloging, metadata can also indicate the context, management, processing, preservation, and use of the resources being described.
- Metadata can come from a variety of sources. Metadata can be supplied by a human (by the creator of the digital file, by an information professional, and/or by an expert or non-expert user). It can also be generated automatically by a computer algorithm, or inferred through a relationship to another resource, such as a hyperlink.
- Metadata continues to accrue during the life of an information object or system. Metadata is created, modified, and sometimes even disposed of at many points during the life of a resource.
- One information object’s metadata can simultaneously be another information object’s data, depending on the kinds of aggregations of and dependencies between information objects and systems. The distinctions between what constitutes data and what constitutes metadata can often be very fluid and may depend on how one wishes to use a certain information object.
Why Is Metadata Important?
Metadata consists of complex constructs that can be expensive to create and maintain. How, then, can one justify the cost and effort involved? The development of the World Wide Web and other networked digital information systems has provided information professionals with many opportunities while at the same time requiring them to confront issues that they have not had occasion to explore previously. Judiciously crafted metadata, wherever possible conforming to national and international standards, has become one of the tools that information professionals are using to exploit some of these opportunities as well as to address some emerging issues, discussed below.
Increased accessibility: Effectiveness of searching can be significantly enhanced through the existence of rich, consistent, carefully crafted descriptive metadata. Metadata can also make it possible to search across multiple collections or to create virtual collections from materials that are distributed across several repositories—but only if the descriptive metadata records are in the same format or have been mapped across the various collections and formats. (Mary Woodley discusses this in more detail in chapter 3, “Metadata Matters.”) Metadata standards that have been developed by different professional communities but include some common data elements (e.g. title, date, creator)—such as Dublin Core, EAD, MARC, BIBFRAME, the Metadata Object Description Schema (MODS), LIDO, and the Text Encoding Initiative (TEI)—are making it easier for users to negotiate between descriptive surrogates of information objects and digital versions of the objects themselves and to search at both the item and collection levels within and across information systems.
Retention of context: Museum, archival, and library repositories do not simply hold objects. They maintain collections of objects that have complex interrelationships and a variety of associations with people, places, movements or styles, and events. In the digital world it is not unusual for a single object from a collection to be digitized and then for that digital surrogate to become separated from both its own cataloging information (descriptive metadata) and its relationship to the other objects in the same collection, resulting in a decontextualized information object. Metadata plays a crucial role in documenting and maintaining important relationships as well as in indicating the authenticity, structural and procedural integrity, and degree of completeness of information objects. In an archive, for example, by documenting the content, context, and structure of an archival record, metadata in the form of an archival finding aid is what helps to distinguish that record from decontextualized information.
Expanding use: Digital information systems for museum and archival collections make it easier to disseminate digital versions of unique objects to users around the globe who, for reasons of geography, economics, or other barriers, might otherwise not have an opportunity to view them. With new communities of users, however, come new challenges concerning how to make the materials most intellectually accessible. These new communities may have significantly different needs, cultural perspectives, language skills, and information-seeking behaviors from those of the traditional users for whom many existing information services were originally designed.
Teaching and learning: K–12 teachers and students may want to search for and use information objects in quite different ways from those of scholarly researchers. Instructors may wish to develop lesson plans or to scaffold learning so that students build on prior knowledge or are introduced to technical terminology. Specialized forms of metadata have been developed to address these needs.9 In addition, the judicious use of controlled vocabularies and folksonomies can enhance access for various types of user groups.
System development and enhancement: Metadata can document changing uses of systems and content, and that information can, in turn, feed back into systems-development decisions. Well-structured metadata can also facilitate an almost infinite number of ways for users to search for information, to present results, and even to manipulate and to present information objects without compromising their integrity.
Multiversioning: The existence of information about, and surrogates of, cultural objects in digital form has heightened interest in the ability to create multiple and variant versions of information objects. This process may be as simple as creating both a high-resolution copy of a digital image for preservation or scholarly research uses and a low-resolution thumbnail image that can be rapidly transferred over a network for quick reference purposes. Or it may involve creating variant or derivative forms to be used, for example, in publications, exhibitions, or schoolrooms. In either case, there must be metadata to relate the multiple versions of a given information object and to capture what is the same and what is different about each version. The metadata must also be able to distinguish what is qualitatively different in the various digitized versions or surrogates from the original physical object or item.
Legal issues: Metadata allows repositories to track the many layers of rights, licensing, and reproduction information that exist for original items as well as for their related information objects and the multiple versions of those information objects. Metadata also documents other legal or donor requirements that have been imposed on original objects and their surrogates—for example, privacy concerns, restrictions on reproductions, and proprietary and commercial interests. (See chapter 4, “Rights Metadata Made Simple” by Maureen Whalen.)
Preservation and persistence: If digital information objects that are currently being created are to have a chance of surviving migrations through successive generations of computer hardware and software, or removal to entirely new delivery systems, they will need metadata that enables them to exist independently of the system that is currently being used to store and retrieve them. Technical, descriptive, and preservation metadata that documents how a digital information object was created and maintained, how it behaves, and how it relates to other information objects will be essential. It should be noted that for the information objects to remain accessible and intelligible over time, it will also be essential to preserve and migrate this metadata and to ensure that it does not become “disconnected” from the object it describes.
System improvement and economics: Benchmark technical data, much of which can be collected automatically by a computer, is necessary to evaluate and refine systems in order to make them more effective and efficient from a technical and economic standpoint. The data can also be used in planning for new systems.
A Note on Metadata, Version Control, Reuse, and Recontextualization
It is worth giving special mention to the roles that metadata increasingly needs to play in supporting some of the particular opportunities of the digital age. Historically, one goal of cataloging was to make it possible to distinguish one version of an object or work from another. One item might be different from another, for example, because it was a second edition of the same work, because it contained printing anomalies distinct from other copies printed at the same time, because it was an abridged or translated version of the original title, or because its title had changed.10 Various standardized practices exist to help catalogers alert potential users to such differences in versions of a work. Today metadata must still be able to elucidate such distinctions. However, it must also be able to help users distinguish between, and trace the changes in, the following:
- Original analog and digitized versions, noting any changes that might have occurred accidentally or deliberately during the digitization process (e.g., digital “repair” of a broken glass lantern slide).
- Digitized and born-digital objects that are created in a range of resolutions to facilitate a variety of distribution mechanisms and uses or that are periodically refreshed, migrated, or rendered into an alternate format for preservation and long-term storage or security purposes.
- Original and renamed, retitled, or reattributed objects. For example, museum objects may be renamed or reattributed or assigned a different creation date because new documentation has come to light. Metadata may also change due to cultural sensitivities or challenges regarding provenance; for example, place names or object names may be changed to their original Native American forms, with English-language names that were assigned after the objects’ creation “demoted” to the status of variants or additional access points.
- Original born-digital materials and revised or updated versions (e.g., websites, reference databases).
- Original analog or born-digital materials that are reused in part or in whole in new digital resources (e.g., personal websites, digital art, or digital music compilations).
- Objects, especially but not only museum objects, that are described collectively in one context within their metadata (e.g., as objects that were all collected at the same time at the same archaeological excavation) but are then taken individually out of that collection and recontextualized (e.g., in a special exhibition of Greek vases from a particular period or an exhibition of paintings relating to a particular theme or subject).
Conclusion and Outstanding Questions
Metadata is like interest: it accrues over time. To extend the metaphor further, wise investments in metadata generate the best return on intellectual capital. Carefully crafted metadata results in the best information management—and the best end-user access—in both the short and the long term. If thorough, consistent metadata has been created, it is possible to conceive of it being used in an almost infinite number of new and even currently unforeseen ways to meet the needs of both traditional and nontraditional users for multiversioning and for data mapping and mining. But the resources and intellectual and technical design issues involved in good metadata development and management are far from trivial. Some key challenges that must be addressed by information professionals as they develop digital information systems and objects are
- identifying which metadata schema or schemas should be applied in order to best meet the needs of the information creator, repository, and users. As mentioned above, selection of an inappropriate schema (e.g., EAD for museum collections that do not share a common provenance) serves neither the collection materials themselves nor the users who wish to find, understand, and use those materials. Also, in many cases, especially with complex objects or hierarchically structured archival and other types of collections, a combination of schemas working together (e.g., MARC or BIBFRAME and/or EAD at the collection level; MARC, Dublin Core, MODS, VRA Core, or LIDO at the item level) may be the best solution.
- deciding which aspects of metadata are essential for the desired goal and how granular each type of metadata needs to be—in other words, how much is enough and how much is too much. There will likely always be important tradeoffs between the costs of developing and managing metadata to meet current needs and creating sufficient metadata that can be capitalized on for future, often unanticipated uses. Metadata creators should remember that good “core” metadata can be a valid approach in both economic and intellectual terms. (See principles 2 and 7 of “Practical Principles for Metadata Creation and Maintenance.”)
- ensuring that the controlled vocabularies, thesauri, and taxonomies (including folksonomies) being applied are the most up-to-date, complete versions of those sets of data values and that they are the appropriate terminologies for the materials being described and for the intended users.
What we do know is that the existence of many types of metadata will prove critical to the continued online and intellectual accessibility and utility of digital resources and the information objects that they contain as well as the original objects and collections to which they relate. In this sense, metadata provides us with the Rosetta stone that will make it possible to decode information objects and their transformation into knowledge in the cultural heritage information systems of the future.
-
An information object is a digital item or group of items, regardless of type or format, that can be addressed or manipulated as a single object by a computer. This concept can be confusing in that it can be used to refer both to digital “surrogates” of original objects or items (e.g., digitized images of works of art or material culture, a PDF of an entire book) and to descriptive records relating to objects and/or collections (e.g., catalog records or finding aids). ↩
-
Anne J. Gilliland-Swetland, “Popularizing the Finding Aid: Exploiting EAD to Enhance Online Browsing and Retrieval in Archival Information Systems by Diverse User Groups,” Journal of Internet Cataloging 4, nos. 3–4 (2001): 199–225. ↩
-
Paul Conway, Preservation in the Digital World (Washington, DC: Commission on Preservation and Access, 1996), http://www.clir.org/pubs/reports/conway2/index.html. ↩
-
Sue McKemmish, Glenda Acland, Nigel Ward, and Barbara Reed, “Describing Records in Context in the Continuum: The Australian Recordkeeping Metadata Schema,” Archivaria 48 (Fall 1999): 3–37. ↩
-
See Roy Tennant, “Metadata’s Bitter Harvest,” Library Journal, July 15, 2004, available at http://roytennant.com/column/?fetch=data/39.xml and the Digital Library Federation’s Multiple Metadata Formats page at http://webservices.itcs.umich.edu/mediawiki/oaibp/index.php/MultipleMetadataFormats. ↩
-
See Anne J. Gilliland et al., “Towards a Twenty-first Century Metadata Infrastructure Supporting the Creation, Preservation and Use of Trustworthy Records: Developing the InterPARES2 Metadata Schema Registry,” Archival Science 5, no. 1 (March 2005): 43–78. ↩
-
Figure 1 is modified from “Information Life Cycle” in C. L. Borgman et al., “Social Aspects Of Digital Libraries” (Final Report to the National Science Foundation, award number 95-28808, presented at the UCLA-NSF Social Aspects of Digital Library Workshop, Graduate School of Education and Information Studies, University of California, Los Angeles, February 15–17, 1996), p. 7, http://works.bepress.com/borgman/181/. ↩
-
See Gilliland et al., “Towards a Twenty-first Century Metadata Infrastructure.” ↩
-
See Dimitrios A. Koutsomitropoulos, Andreas D. Alexopoulos, Georgia D. Solomou, and Theodore S. Papatheodorou, “The Use of Metadata for Educational Resources in Digital Repositories: Practices and Perspectives,” D-Lib 16, nos. 1–2 (January–February 2010), http://www.dlib.org/dlib/january10/kout/01kout.html. ↩
-
According to the Functional Requirements for Bibliographic Records (FRBR) conceptual model, these are different “expressions” and/or “manifestations” of a work; see http://www.ifla.org/publications/functional-requirements-for-bibliographic-records. Note that the definition of a “work” (and the conceptual model) can differ considerably for unique works of art or architecture, as opposed to literary works or musical compositions, for which the FRBR model is ideal. See Murtha Baca and Sherman Clarke, “FRBR and Works of Art, Architecture, and Material Culture,” in Understanding FRBR: What It Is and How It Will Affect Our Retrieval Tools, ed. Arlene G. Taylor (Westport, CT: Libraries Unlimited, 2007), 103–10. ↩